A regular expression (also known as regex, and regexp) is a sequence of characters used by various programming languages such as python, Linux tools such as grep, awk, sed, etc. to match one or more strings.
For instance, the regex "R.*x" matches with strings "Regex", and "Regular Expression in Linux", etc.
Despite being super useful, there is not a single standard that is followed everywhere. For example, we have GNU Regex, POSIX Regex, Perl Regex, etc.
However, there are very few variations across these standards. For instance, sed in Linux and Mac OS follow standards slightly different from each other. Here, in this article, I will be focusing mainly on the GNU Regex using grep command in Linux. At the same time, I will also be mentioning these variations which come to my mind.
Regex Is Not a Shell Pattern
I need to warn you that regexp is completely different from the zsh or bash's glob (also called shell-pattern).
For example, *.mp4 in shell pattern means any filename ending with .mp4. On the other hand, the star (*) at the start of a regex is a null character.
Similarly, ?, () and | have different meanings.
At the same time, you need to prevent the shell from interpreting your regex as a shell pattern. For this, you need to surround it with double quotes (preferably single quotes).
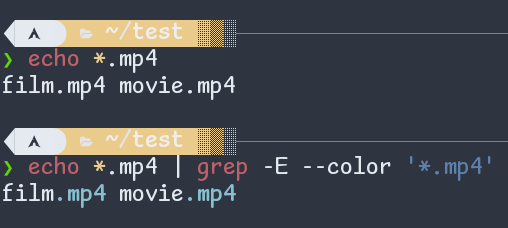
Fig: the difference between regex and shell patterns (globs)
Special and Ordinary Characters in Regular Expression
Ordinary Characters
Any character other than the .?\*+{|()\[\\^$ are called ordinary characters and they are interpreted as they are.
For the example given below, the regex linux is made of ordinary characters and hence it is interpreted as it is.
Fig - Ordinary characters in regular expressions
Note: By the way, If a line does not contain the given regex pattern, grep does not print that line. Therefore, in the above example, the first line is omitted.
Special Characters
The characters .?*+{|()[\^$ are called special characters (also known as metacharacters) since they have special meanings in the regex:
| Regular expression | Meaning |
| ------------------ | ------------------------------------------------------------------------------ | ---------------------------------------------- |
| . | any single character |
| * | the preceding item matching zero or more times |
| + | the preceding item matching one or more times |
| ^ | beginning of the line |
| $ | end of the line |
| ? | the preceding item is optional |
| [ | list of characters, range of characters, named classes |
| { | used for interval expression |
| | | the infix Operator (the OR Alternate Operator) |
| ( | used for grouping |
| \ | have meanings in combination with other characters; ex- \b, \<, \w, etc. |
Table: Special Characters in Regular Expression
Although these characters are special characters, you can force your regex engine to treat them as ordinary characters by prepending them with a backslash. Example -
Fig: prepend a backslash to treat metacharacters as ordinary characters
Now I will be explaining all these special characters in the upcoming headings with examples.
Dot (.) in Regular Expression
Dot will match any single character.
In the following example, only "fix" from the first line is matched. Here, "i" is equated as the dot. In the second line, there is no such character between f and x and hence, nothing is matched in the second line.
Fig: Dot (.) in regexp
Caret (^) in Regex
The caret (^) means to match an empty string at the start of a line.
For example, the following command searches for the "linux" at the beginning. Since the second line does not have "linux" at the start, hence that is not printed.
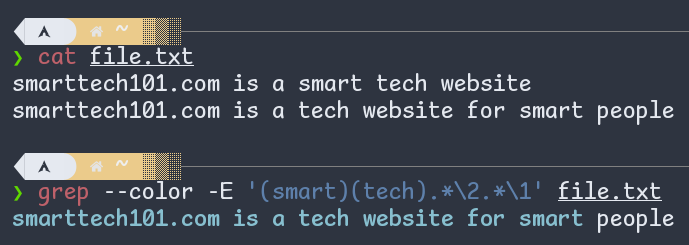
Fig: Caret (^) in regexp
Dollar ($) in Regex
The dollar is used to match an empty string at the end of a line. For the following example, only the second line is matched because only that one has "linux" at the end.

Figure: - Dollar ($) in regexp
Note: The charet (^) and dollar ($) are also called regex anchors.
Character Class: Bracket Expression ([ ]) in Regexp
Character Class (also known as Character Set) is a list of characters in the [] to match any one character from the list. There are many types:
| [az] | the character “a” OR “z” |
| [a-z] | any letter from a to z (lowercase) |
| [A-Z] | any letter from A to Z (uppercase) |
| [A-Za-z] | any letter |
| [0-9] | any number |
| [-az] | any one character out of the three |
| [^abc] | negates [abc] i.e. matches any character except a, b, c (called Negated Character Class) |
Table: Bracket Expressions
Note 1: Letters and numbers have different meanings in different countries and languages. The above table is for the traditional C locale. In simple words, if your work is based on English then it should work fine.
Explanations with examples:
- In the following example, regex
i[sn]matches eitherisorin.
![Fig: [sn] in regex equals to s or n.](/images/2022-02-26_164452.856765815.png)
Fig: [sn] equals to s or n.
- The dash (
-) is used for "Range Expression". In the example given below, the[0-9]matches with only the digits..
![Fig: [0-9] equals to any digit](/images/image-10.png)
Fig: [0-9] equals to any digit
[A-Za-z]means any alphabetic character as shown below:
![Fig: [A-Za-z] equals to any alphabetic character](/images/image-12.png)
Fig: [A-Za-z] equals to any alphabetic character
- To include the literal dash in your list as well, put the dash at the beginning in the bracket.
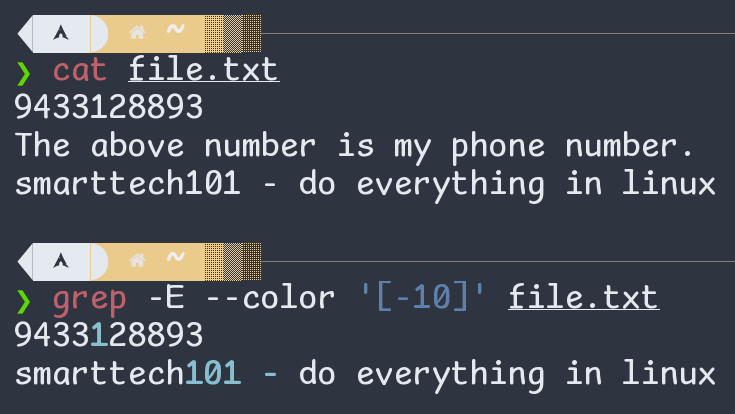
Figure - including literal dash in the bracket
- Negated Character Class: Continuing with the above example,
[^-10]just matches any character other than the-, 1, 0.
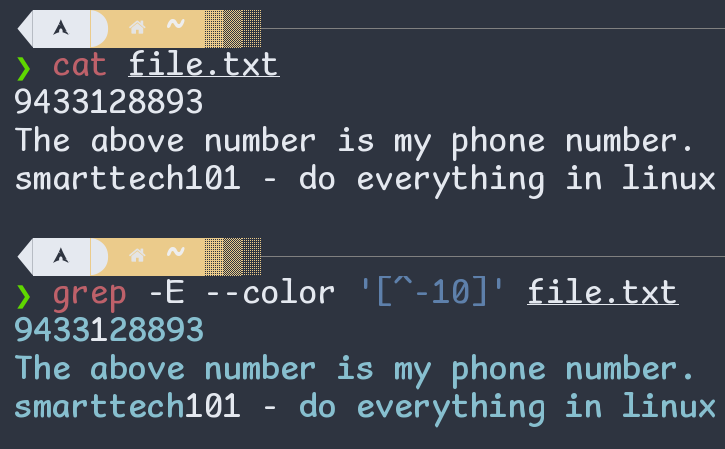
Figure: Negated Character Class in Regular Expression
The above-mentioned Character Classes are sufficient to create any list. But before creating any convoluted list such as [A-Za-z0-9], you can also use also corresponding Named Classes explained below.
Named Class (aka Named Set) in Regex
Named Classes are predefined character classes. For example, [:alpha:] equals to any upper or lowercase alphabet
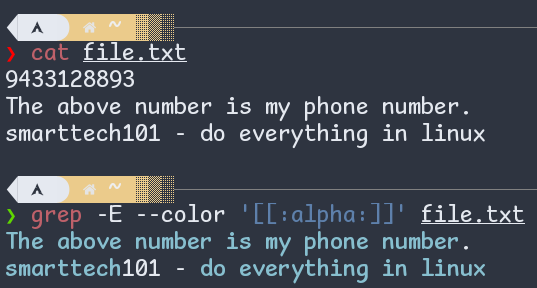
Figure: Named Class in Regular Expression
Here is a list of widely used named classes (source: [man grep](//www.gnu.org/software/grep/manual/grep.html), man gawk):
[:lower:]- lowercase letters[:upper:]- uppercase letters[:alpha:]- alphabets[:digit:]- digits[:alnum:]- alphabets or numbers i.e.[A-Za-z0-9][:punct:]- punctuation characters (characters that are not letter, digits, control characters, or space characters)[:space:]- any space character (space, horizontal and vertical tabs, newline, carriage return, and formfeed).[:blank:]- space or tab[:cntrl:]- control characters[:print:]- printable characters i.e.[:punct:],[:alnum:], space[:graph:]- graphical characters i.e.[:alnum:]and[:punct:][:xdigit:]- hexadecimal digits
Note 1: Special Characters lose their special meanings in the bracket. However, some of them can get it back by their special placement in the bracket. For instance, you need to place ^ anywhere but first, dash (-) at first, and ] at the first position to get back their special meanings.
Note 2: The Named Classes can be included with other regular expressions in the brackets. For instance, [[:upper:][:lower:]] equals both upper and lower alphabets.
Backslash Based Regex (\b, \B, \w, \W, \s, \S, \>, \<)
\w is a word-constituent character (letter, digit, or underscore). Anything other than that is \W (non-word-constituent character). Ex -
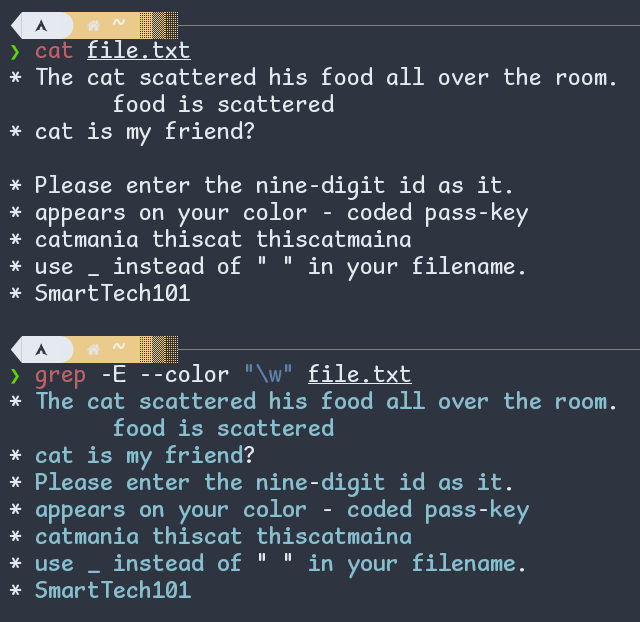
Fig: \w in regex; text credit: a brilliant StackExchange question
\s is [[:space:]] mentioned above. \S (non-whitespace) is the exact opposite.
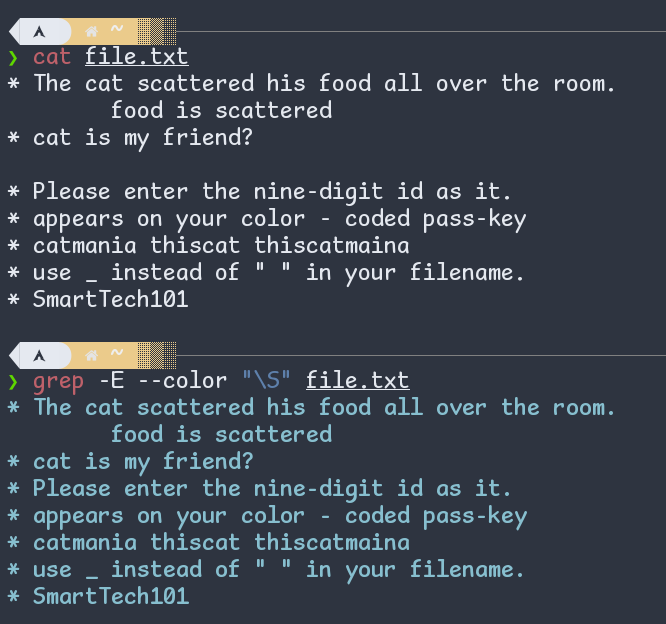
Fig: \s and \S in regex; see how the regex is not matching the empty line.
\b equals to an empty string at the edge of a word (source: grep's manual). In GNU gawk command of Linux, it is \y.
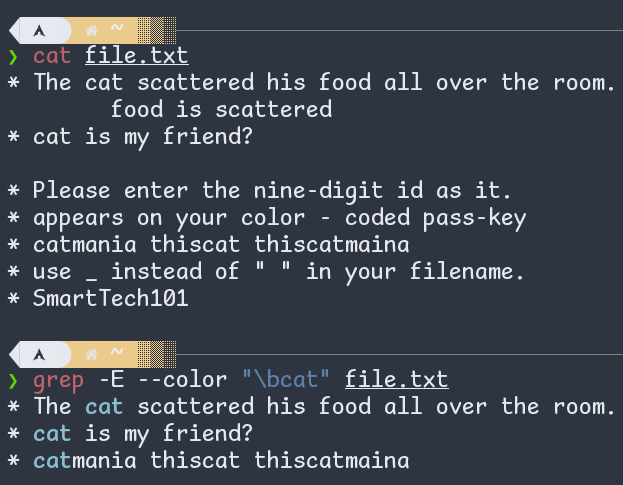
Figure: \b in regular expression
\B matches to an empty string provided it’s not at the edge of a word. (source: man grep)
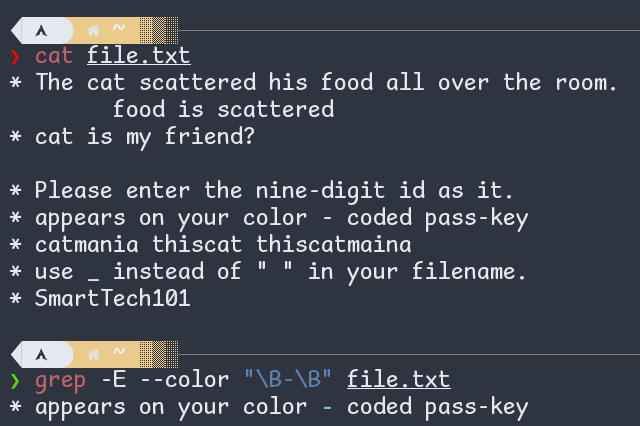
Figure: \B in regex
\< and \> match the empty string at the beginning and end of a word (respectively).
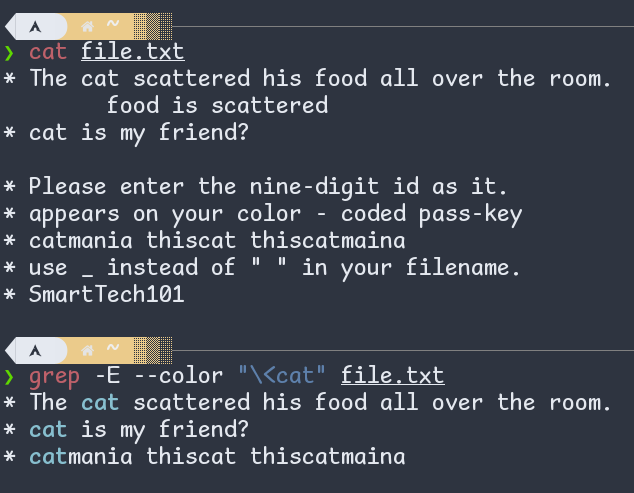
Figure: \< in regular expression
Repetition Operators in Regular Expression (*, +, ?, {n,m})
| Regular expression | Meaning |
| ------------------ | -------------------------------------------------- |
| ? | the preceding item is optional |
| * | the preceding item matching zero or more times |
| + | the preceding item matching one or more times |
| {n} | the preceding item matching exactly n times |
| {n,} | the preceding item matching n or more times |
| {,m} | the preceding item matching m or less than m times |
| {n,m} | the preceding item matching n to m times |
Table: Repetition Regex; source: grep's man page
Now I will describe them with examples.
- Star (
*): In the following example, "f.*x" means "f, then any character (.) repeated zero or more times (*), and then x".
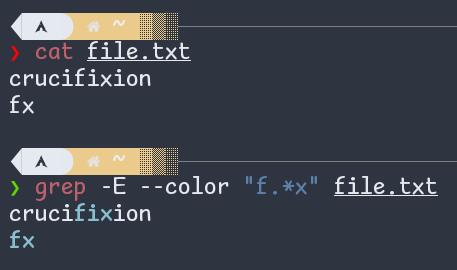
Figure: regex star (*)
- Plus (
+): Similarly, "f.+x" means "f, then any character (.) repeated one or more times (+), and then x".
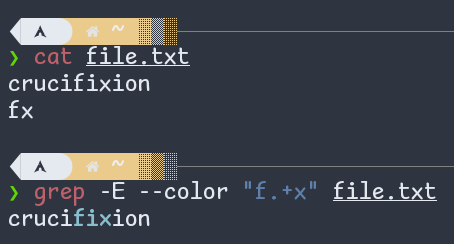
Figure: Plus (+) in regex
- Question Mark (
?) in regex makes previous item optional. Therefore, in the following example,https?matches with bothhttpandhttps:
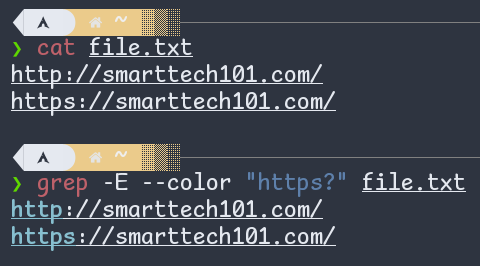
Figure: Question mark (?) in regex
{n}: For the following example,.{5}means any character (dot) repeated 5 times. Therefore, first grep prints any 5 character. Then it prints another 5 character from the remaining part. And then again it prints the next 5 character. Now, the text does not have 5 character left and hence nothing is printed.
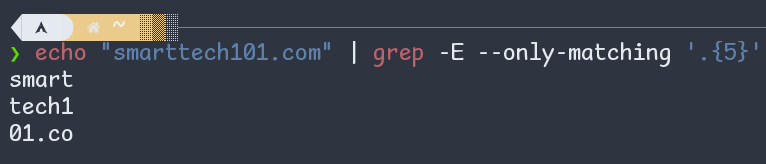
Figure: Curly braces {n} in regex
{n,},{,m},{n,m}, similarly, means the preceding item repeated n or more, m or less, n to m times respectively.
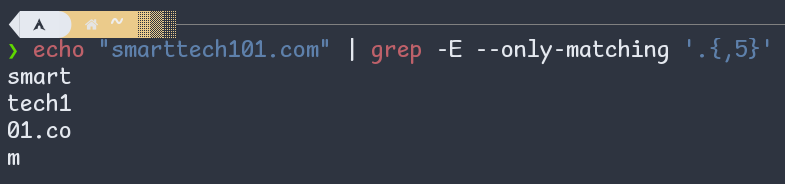
Figure: curly braces {,m} in regex
Alternation (or Infix) Operator (|) in Regexp
When you insert an Infix Operator | between two regular expressions, the regex engine chooses one of the two expressions.
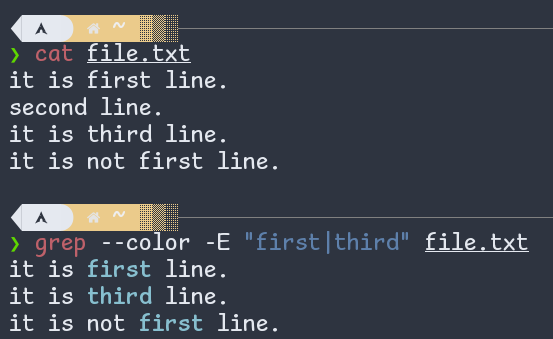
Fig: Infix (Alternate) Operator In Regexp
Grouping in Regex
You can put a group of characters in parenthesis and force the regex engine to treat them as a unit.
For instance, in the following example, a group of characters smart is repeated twice. On the other hand, regex smart2 means smartt.

Figure: Parenthesis to group the regex
Back-references in Regexp
Back-references in a regex are denoted by \n, where n is a number and they "refer back" to the nth parenthesized regex.
For example given below, \2 refers to the second parenthesized part i.e. tech and \1 to the first parenthesized part i.e. smart. In other words, \2 is replaced with the second one and \1 with the first.
Figure: Backreferences in regexp
Conclusion
That's all folks. If you want to revise it quickly, just have a quick look at the given tables.
Thanks for reading and if you have any suggestions/problems, please comment below.