Grep command in Linux is used to "grapple" any type of strings from all sorts of files. In this article, I will talk about its basic applications with examples.
Basics of grep command in Linux
Basic Syntax:
grep [OPTION...] PATTERNS [FILE...]In the above syntax,
- OPTION is also called "flags". The
--recursiveand-rare few of the options of the grep. The three dots...indicate that you can use more than one option. - Here, PATTERNS are special types of words being searched. In the example given below it is "it".
- FILE is the name of the file where you want to search for your PATTERN. For the following example, it is "file.txt"
For example, The following grep command prints all the lines having the pattern "it" from the file "file.txt".
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ grep "it" file.txt
it is first line.
it is third line.If you do not provide any filename and do not use the flag --recursive, grep searches from the standard input (|, and <).
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ cat file.txt | grep "it"
it is first line.
it is third line.
[ajay@lenovo ~]$ < file.txt grep "it"
it is first line.
it is third line.
[ajay@lenovo ~]$ grep "it" < file.txt
it is first line.
it is third line.Similarly, the file name dash "-" means the standard input as in the following example:
[ajay@lenovo ~]$ free --human --total
total used free shared buff/cache available
Mem: 6.7Gi 2.0Gi 139Mi 43Mi 4.5Gi 4.3Gi
Swap: 14Gi 89Mi 14Gi
Total: 21Gi 2.1Gi 14Gi
[ajay@lenovo ~]$ free --human --total | grep "Total" -
Total: 21Gi 2.1Gi 14GiHow to make grep search case-insensitively
By default, grep searches case-sensitively. This means, grep will consider "smarttech101", for example, and "SmartTech101" two different words.
To make grep ignore the case, use the flag -i or --ignore-case.
Example:
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ grep --ignore-case "It" file.txt
it is first line.
it is third line.How to grep multiple patterns
If you use --regexp or -e multiple times, grep will search for all patterns given.
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ grep --regexp="first" --regexp="second" file.txt
it is first line.
second line.Alternatively, you can put all of your patterns in a file separated by a newline character and then use that file with the flag --file or -f. Example:
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo test]$ cat pattern-file.txt
first
second
[ajay@lenovo test]$ grep --file=pattern-file.txt file.txt
it is first line.
second line.Note 1: You can use both the flags --file and --regexp together. In that case, grep will search for all the patterns together.
Note 2: When the flag --regexp used only once, grep behaves normally as shown below:
[ajay@lenovo ~]$ grep --regexp="first" file.txt
it is first line.How to grep pattern(s) in all files in a directory recursively
To search for a pattern in all the existing files in the current working directory, you need to use the flag --recursive or -r.
[ajay@lenovo test]$ ls -1
file2.txt
file.txt
[ajay@lenovo test]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo test]$ cat file2.txt
I means first
II means 2nd
III means third
[ajay@lenovo test]$ grep --recursive "first"
file2.txt:I means first
file.txt:it is first line.📓 Notes: to remove the filename, use the flag --no-filename or -h:
[ajay@lenovo test]$ grep --no-filename --recursive "first"
I means first
it is first line.How to print the line number as well in grep
The flag --line-number or -n prepends each line in the output with the serial number of that line in its input file.
For instance, in the following example, the lines "it is third line." and "III means third" are found in the third line of their respective files. Therefore, '3' is being prepended in both lines of the output.
[ajay@lenovo test]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo test]$ cat file2.txt
I means first
II means 2nd
III means third
[ajay@lenovo test]$ grep --line-number "third" file.txt file2.txt
file.txt:3:it is third line.
file2.txt:3:III means thirdHow to get colored output using grep
Grep outputs in the color using the escape sequences. For this, use the flag --color=WHEN, where WHEN is
alwaysto output in color alwaysneverto never output in colorauto: grep uses the escape sequences when it outputs on the terminal. When it outputs into the pipe, it does not use the sequences.
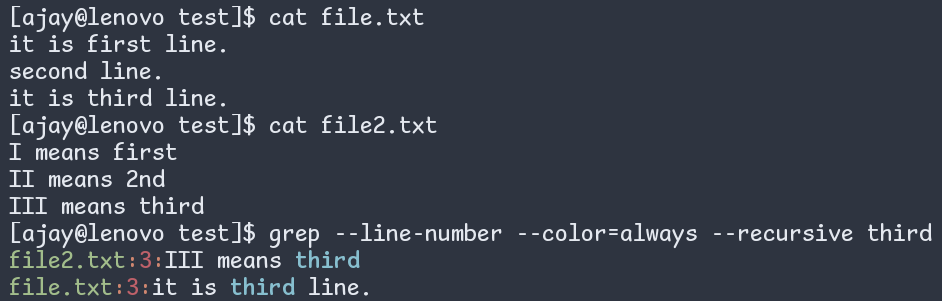
Figure: grep with colored output
Note 1: If you mention only the flag --color and not the =WHEN, grep will assume auto. Ex -
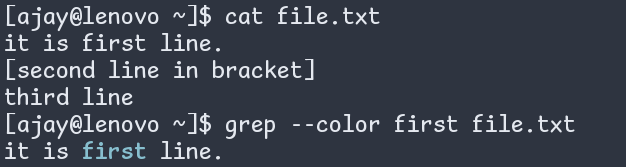
Figure: grep printing in color by just using the --color
Note 2: The flag --color=auto is very handy. Hence, you can set an alias in your .bashrc or .zshrc file.
Fun Point 😃: This flag, when combined with --line-number and --recursive is one of the most powerful applications of grep. Suppose you want to see how you used the tee command in the past in your scripts. But you do not know the locations of these scripts. To know the locations, you need to execute the following command:
[ajay@lenovo test]$ grep --line-number --color=always --recursive "tee" ~/.my_scripts/Output:
Figure: grep with colored output
How to print only the matching part in grep
In all of the above examples, grep is printing the whole lines in which it found the pattern. To print only the matching pattern, use the flag --only-matching or -o.
[ajay@lenovo test]$ echo "smarttech101smarttech101" | grep --only-matching "smart"
smart
smartPlease note that grep prints all the matching patterns on separate lines even if they were part of the same line. This is clearly visible in the above example.
Application: You can use this flag for web scrapping (i.e. get only the required text from HTML pages).
How to grep only the non-matching lines
Using the flag --invert-match or -v, you can invert the matching i.e. grep will print out only those lines which do not have the PATTERN.
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ grep --invert-match "second" file.txt
it is first line.
it is third line.How to make grep to output only the number of matching lines
For this, use the --count or -c flag. Now, grep will output only the number of matching lines corresponding to each file. For example -
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ cat file2.txt
I means first
1st also means first
II means 2nd
III means third
[ajay@lenovo ~]$ grep --count "first" file.txt file2.txt
file.txt:1
file2.txt:2In the above example, the string "first" is found only once in the file.txt but twice in the file2.txt.
When you use this flag --count with the flag --invert-match, grep will output the number of non-matching lines. For example -
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
[ajay@lenovo ~]$ cat file2.txt
I means first
1st also means first
II means 2nd
III means third
[ajay@lenovo ~]$ grep --invert-match --count "first" file.txt file2.txt
file.txt:2
file2.txt:2How to search directly for a word using grep
For this, use the flag --word-regexp or -w. For example,
[ajay@lenovo ~]$ echo -e 'ajay jay patel\najay\njay patel\najay jay\njaya prada' | grep --word-regexp --color "jay"
ajay jay patel
jay patel
ajay jay
Here, in the above example,
- If "jay" comes at the start of the line, it should be followed by the non-word characters (
\W) which are anything other than alphabets, numbers, and underscore. Hence, the third line from the echo command's output is matched, but not the fifth one. - If "jay" comes at the end of the line, it should be preceded by
\W. Hence, second line does not match, but the fourth line matches. - If "jay" comes in between the line, it should be both followed and preceded by
\W. The first line from the echo illustrates this.
How to search directly for a line using grep
To search for a line, use the flag --line-regexp or -x. Example -
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
it is not first line.
[ajay@lenovo ~]$ grep --line-regexp "it is first line." file.txt
it is first line.What is PATTERN in grep command in Linux
There are four types of patterns in grep - extended regular expressions (EREs), fixed strings, basic regular expressions (BREs), and Perl-compatible regular expressions (PCREs).
Extended Regular Expressions in grep
This is my favorite since I find myself using it most of the time. To use this, use the flag -E or --extended-regexp.
The command egrep is the same as grep --extended-regexp. But, avoid using that since the egrep has been deprecated, and hence in the future, it might not work.
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
it is not first line.
[ajay@lenovo ~]$ grep --extended-regexp "first|third" file.txt
it is first line.
it is third line.
it is not first line.In the above example, grep will search for the "first" OR "third". Here, is a table of the most widely used regular expressions and their meanings:
| Regular expression | Meaning |
| ------------------ | ------------------------------------------------------------------------------------------------ |
| . | any single character |
| * | the preceding item matching zero or more times |
| + | the preceding item matching one or more times |
| ^ | beginning of the line |
| $ | end of the line |
| ? | the preceding item is optional |
| [az] | the character "a" OR "z" |
| [a-z] | any letter from a to z (lowercase) |
| [A-Z] | any letter from A to Z (uppercase) |
| [A-Za-z] | any letter |
| [0-9] | any number |
| {n} | the preceding item matching exactly n times |
| {n,} | the preceding item matching n or more times |
| {,m} | the preceding item matching m or less than m times |
| {n,m} | the preceding item matching n to m times |
| \s | any space character (space, horizontal and vertical tab, and newline, carriage return, formfeed) |
| \S | any Non-whitespace character (i.e. exact opposite of \s) |
Table: The most widely used regular expressions and their meanings; source: man page
Note: the above meanings are only for the traditional C locale. In simple words, if your work is based on English then it should work fine.
Regular expressions are extremely useful in Linux, Windows, and all programming languages. Therefore, I recommend you to have a look at my article on regular expressions.
Basic Regular Expressions in grep
For this, use the flag -G or --basic-regexp. This pattern is the default pattern. Therefore, if you do not provide any flag corresponding to these four patterns, grep will assume the given pattern to be the Basic Regular Expressions (BREs).
For the GNU version of grep, basic (BREs) and Extended Regular Expressions (EREs) have the "same functionality". To know if your grep is the GNU grep or not just search for the "GNU" word in the bottom line of the man page (man grep). If the "GNU" word is there, your grep is highly likely to be the GNU grep.
The "same functionality" does not mean that the BREs' syntax is the same as that of the EREs. In BREs, meta-characters ?, +, {, |, (, and ) lose their special meaning. You need to prepend the backslashes to get back their special meanings. Example:
[ajay@lenovo ~]$ cat file.txt
it is first line.
second line.
it is third line.
it is not first line.
[ajay@lenovo ~]$ grep "first\|third" file.txt
it is first line.
it is third line.
it is not first line.Perl-Compatible Regular Expressions
In order to use this, you need the flag --perl-regexp or -P.
This is much broader than the Extended Regular Expressions (EREs). For instance, non-greedy matching (.*?) is not available in the EREs, but in this, it is available.
[ajay@lenovo ~]$ # greedy
[ajay@lenovo ~]$ echo "smarttech101smarttechsmart" | grep --extended-regexp --only-matching 'smart.*smart'
smarttech101smarttechsmart
[ajay@lenovo ~]$ # non-greedy
[ajay@lenovo ~]$ echo "smarttech101smarttechsmart" | grep --perl-regexp --only-matching 'smart.*?smart'
smarttech101smartTo know more about the Perl-regex, see the man pages (man 3 pcresyntax and man 3 pcrepattern).
Fixed strings in grep
If you want the grep to interpret your searched string as a fixed string instead of the grep's default basic regular expression, you need to use the flag --fixed-strings or -F.
This becomes useful when your texts have a lot of regular expression metacharacters such as brackets, dash, star, dot, etc. Example -
[ajay@lenovo ~]$ cat file.txt
it is first line.
[second line in bracket]
third line
[ajay@lenovo ~]$ cat file.txt | grep --fixed-strings "["
[second line in bracket]One more thing to note is that just like egrep, there is fgrep equivalent to grep --fixed-strings. Both fgrep and egrep commands are deprecated and hence they can be removed in the future.
Grep on files and/or regex starting with a literal dash -
When you use grep with regexp starting with a -, you get errors such as below:
[ajay@lenovo ~]$ echo '00:02:03-00:05:45' | grep --extended-regexp --only-matching '-.*45'
grep: invalid option -- '.'
Usage: grep [OPTION]... PATTERNS [FILE]...
Try 'grep --help' for more information.The reason is that grep considers this regex as another flag. Therefore, to prevent the grep from such consideration, use the end of the option notifier -- as shown below:
[ajay@lenovo ~]$ echo '00:02:03-00:05:45' | grep --extended-regexp --only-matching -- '-.*45'
-00:05:45The same goes for a file. If a filename contains - at the beginning, you will get errors. Use -- to avoid that.
😃 Fun Fact: Many Linux tools such as touch, and ls use -- to indicate the end of the option. This coherency is one of the things I love about Linux.
Concluding Remarks
That was all about the basics of the grep command in Linux. I have tried my best to include as many examples as possible with every fact mentioned here - This is the hallmark of this blog smarttech101.com.
At the same time, I have tried to minimize errors as much as possible. But if there are still some inadvertent errors, please notify me using the comment section below. And if you have any problems, mention them in the comment section. I will be pleased to help you.